Navigating The World Of Classification With Scikit-learn: A Comprehensive Guide
Navigating the World of Classification with scikit-learn: A Comprehensive Guide
Related Articles: Navigating the World of Classification with scikit-learn: A Comprehensive Guide
Introduction
With enthusiasm, let’s navigate through the intriguing topic related to Navigating the World of Classification with scikit-learn: A Comprehensive Guide. Let’s weave interesting information and offer fresh perspectives to the readers.
Table of Content
- 1 Related Articles: Navigating the World of Classification with scikit-learn: A Comprehensive Guide
- 2 Introduction
- 3 Navigating the World of Classification with scikit-learn: A Comprehensive Guide
- 3.1 Unveiling the Essence of Classification
- 3.2 The Diverse Landscape of Classification Algorithms
- 3.3 Navigating the Workflow: Building and Evaluating Classification Models
- 3.4 Practical Applications: Real-World Scenarios
- 3.5 FAQs: Demystifying Classification with scikit-learn
- 3.6 Tips for Effective Classification Modeling
- 3.7 Conclusion: Embracing the Power of Classification
- 4 Closure
Navigating the World of Classification with scikit-learn: A Comprehensive Guide

In the realm of machine learning, classification stands as a cornerstone technique used to predict the category or class to which a given data point belongs. This process, often likened to sorting objects into distinct bins, finds applications across a vast spectrum, from identifying spam emails to diagnosing medical conditions. Scikit-learn, a powerful Python library, provides a robust framework for building and deploying classification models, enabling data scientists and machine learning practitioners to extract valuable insights from their datasets.
This article aims to provide a comprehensive guide to classification within the scikit-learn ecosystem, exploring its fundamental concepts, key algorithms, and practical implementation strategies. We will delve into the core principles that underpin classification, examining the various algorithms available and their strengths and limitations. Furthermore, we will equip readers with the knowledge and tools to build, evaluate, and deploy their own classification models using scikit-learn.
Unveiling the Essence of Classification
At its core, classification involves training a model on a dataset with labeled examples, where each example belongs to a specific class. The model learns the underlying patterns and relationships between features and class labels. Once trained, the model can predict the class of unseen data points based on their features.
Consider the illustrative example of email classification. A model trained on a dataset of emails labeled as "spam" or "not spam" learns to recognize patterns associated with spam emails, such as excessive use of exclamation marks, suspicious links, or irrelevant content. When presented with a new email, the model analyzes its content and predicts whether it is spam or not based on the learned patterns.
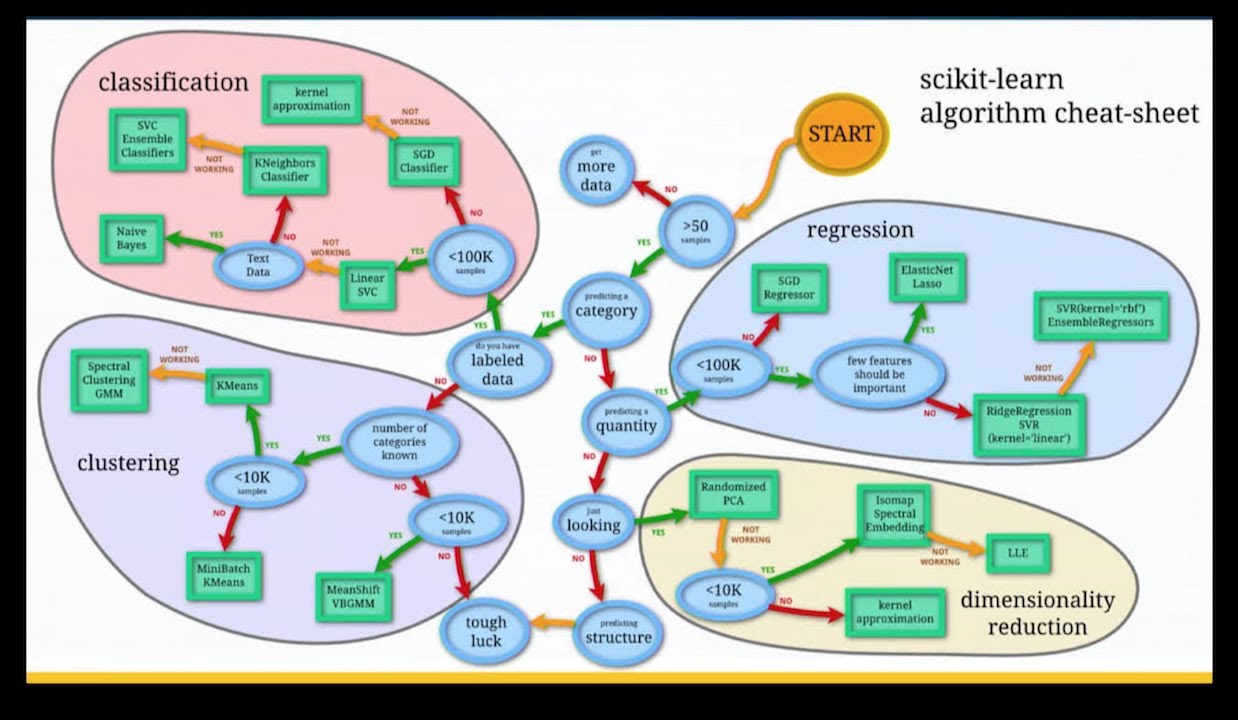
The Diverse Landscape of Classification Algorithms
Scikit-learn offers a rich array of classification algorithms, each with its unique strengths and suited for different types of data and problem scenarios. Some of the most widely used algorithms include:
1. Logistic Regression: This algorithm, despite its name, is a powerful classification technique that models the probability of a data point belonging to a particular class. It excels in situations where the decision boundary between classes is linear or can be approximated by a linear function.
2. Support Vector Machines (SVMs): SVMs are renowned for their ability to handle high-dimensional data and complex decision boundaries. They aim to find the optimal hyperplane that separates data points belonging to different classes with the maximum margin, leading to robust and accurate predictions.
3. Decision Trees: Decision trees are tree-like structures that partition the data space recursively based on feature values, leading to a series of decisions culminating in a class prediction. They are highly interpretable and can handle both numerical and categorical features.
4. Random Forests: This ensemble method combines multiple decision trees to improve prediction accuracy and reduce overfitting. Random forests leverage the power of multiple models to achieve better generalization performance.
5. Naive Bayes: Based on Bayes’ theorem, this algorithm assumes independence between features and uses prior probabilities to calculate the posterior probability of a data point belonging to a particular class. It is known for its simplicity and efficiency, particularly in text classification tasks.
6. K-Nearest Neighbors (KNN): This algorithm classifies a data point based on the majority class of its k nearest neighbors in the feature space. It is a non-parametric method, meaning it does not make assumptions about the underlying data distribution.
7. Gradient Boosting Machines (GBMs): GBMs are powerful ensemble methods that sequentially build weak learners, each correcting the errors of its predecessors. They are known for their high accuracy and ability to handle complex datasets.
8. Neural Networks: These complex models, inspired by the human brain, consist of interconnected nodes organized in layers. They are particularly adept at handling nonlinear relationships and complex patterns in data, often achieving state-of-the-art performance in various classification tasks.
Navigating the Workflow: Building and Evaluating Classification Models
Building and evaluating classification models with scikit-learn involves a series of well-defined steps:
1. Data Preparation: This step involves cleaning, transforming, and preparing the data for model training. Tasks may include handling missing values, encoding categorical features, and scaling numerical features.
2. Model Selection: Choosing the appropriate classification algorithm depends on the nature of the data, problem requirements, and desired model characteristics.
3. Model Training: This involves fitting the selected model to the prepared training data, allowing the model to learn the relationships between features and class labels.
4. Model Evaluation: Assessing the performance of the trained model is crucial to ensure its reliability and accuracy. Various metrics, such as accuracy, precision, recall, F1-score, and AUC, are commonly used to evaluate classification models.
5. Model Optimization: Fine-tuning model hyperparameters can significantly improve performance. Techniques like grid search and cross-validation are employed to find the optimal hyperparameter settings.
6. Model Deployment: Once the model has been evaluated and deemed satisfactory, it can be deployed for real-world applications, allowing predictions on new data points.
Practical Applications: Real-World Scenarios
Classification techniques find applications in a wide range of domains, including:
1. Healthcare: Diagnosing diseases, predicting patient outcomes, and identifying potential risks.
2. Finance: Fraud detection, credit risk assessment, and customer segmentation.
3. E-commerce: Recommending products, personalizing shopping experiences, and identifying fraudulent transactions.
4. Marketing: Customer churn prediction, targeting campaigns, and sentiment analysis.
5. Security: Intrusion detection, spam filtering, and malware analysis.
6. Natural Language Processing: Text classification, sentiment analysis, and topic modeling.
7. Image Recognition: Object detection, image classification, and facial recognition.
FAQs: Demystifying Classification with scikit-learn
1. What are the key differences between classification and regression?
Classification deals with predicting categorical labels, while regression focuses on predicting continuous values. In classification, the output is a discrete category, such as "spam" or "not spam," while in regression, the output is a continuous value, such as a price or temperature.
2. How do I choose the right classification algorithm?
The choice of algorithm depends on factors such as the nature of the data, the complexity of the decision boundary, the desired model interpretability, and computational resources.
3. What are the common evaluation metrics for classification models?
Common metrics include accuracy, precision, recall, F1-score, and AUC. These metrics provide insights into different aspects of model performance, such as overall accuracy, ability to correctly identify positive cases, and ability to avoid false positives.
4. How do I handle imbalanced datasets in classification?
Imbalanced datasets, where one class is significantly more prevalent than others, can lead to biased models. Techniques like oversampling, undersampling, and cost-sensitive learning can be used to address this issue.
5. What are the benefits of using scikit-learn for classification?
Scikit-learn offers a comprehensive and user-friendly framework for building and deploying classification models. It provides a rich set of algorithms, tools for data preparation and evaluation, and seamless integration with other Python libraries.
Tips for Effective Classification Modeling
1. Data Quality is Paramount: Ensure data is clean, consistent, and relevant to the classification task.
2. Feature Engineering Matters: Carefully select and engineer features that are informative and predictive.
3. Explore Multiple Algorithms: Experiment with different algorithms to find the best fit for your data and problem.
4. Evaluate Thoroughly: Use appropriate evaluation metrics to assess model performance and identify areas for improvement.
5. Optimize Hyperparameters: Fine-tune model hyperparameters to achieve optimal performance.
6. Consider Ensemble Methods: Leverage the power of ensemble methods to improve accuracy and robustness.
7. Interpret Model Results: Understand the model’s predictions and identify potential biases or limitations.
8. Document Your Work: Maintain clear documentation of the data, algorithms, and model performance for reproducibility and future reference.
Conclusion: Embracing the Power of Classification
Classification, a fundamental machine learning technique, empowers us to extract valuable insights from data, enabling informed decision-making across diverse domains. Scikit-learn, with its comprehensive suite of algorithms, tools, and resources, provides a powerful platform for building, evaluating, and deploying classification models. By understanding the core concepts, exploring various algorithms, and following a structured workflow, practitioners can leverage the power of classification to solve real-world problems and unlock new possibilities.






Closure
Thus, we hope this article has provided valuable insights into Navigating the World of Classification with scikit-learn: A Comprehensive Guide. We hope you find this article informative and beneficial. See you in our next article!